
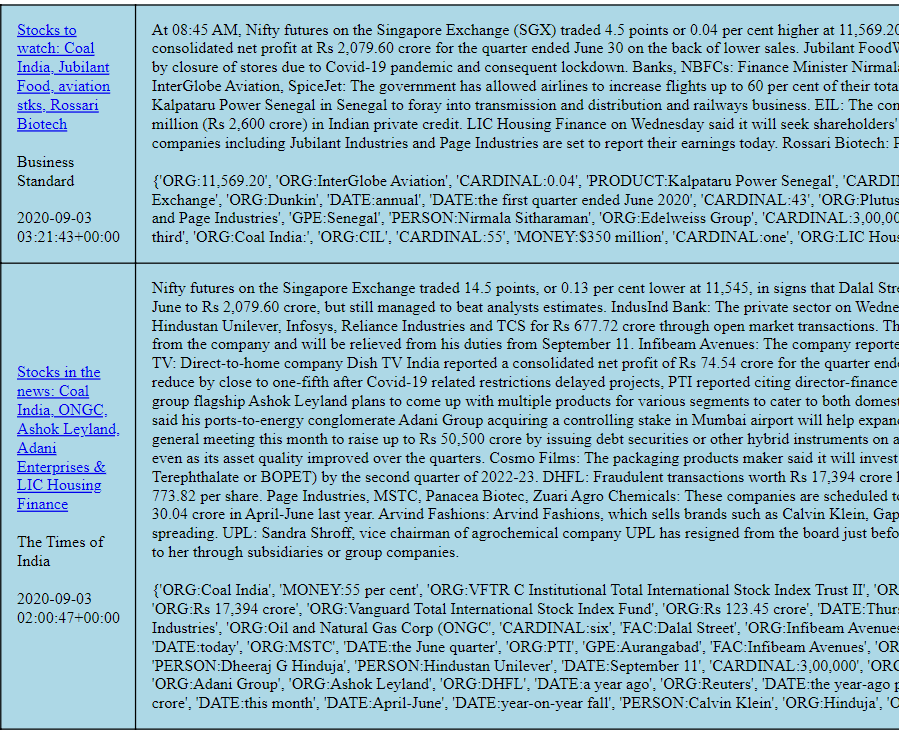
How does one know if two news items have the same story?
This is a problem for news aggregators. Multiple sources supply news content that are paraphrases of each other. One major news event and the screen is inundated with the same story, in different words. In fact thanks to Reuters, AP and other news agencies, most sources would print the same copy verbatim.
Can an algorithm identify news items that are paraphrases of each other?
I try out an NLP concept called Named Entity Recognition. The assumption is that if two stories have the name of the same person(s) and organization(s), is referring to the same event, is quoting the same numbers and so on, and so forth, then it is highly likely that the two stories are paraphrases of each other.
Ideally, we would create a dataset of a 100,000 pairs of similar and dissimilar stories and run supervised learning on it.
I have tried to formulate this problem as a binary classification and multi-label classification machine learninig problem:

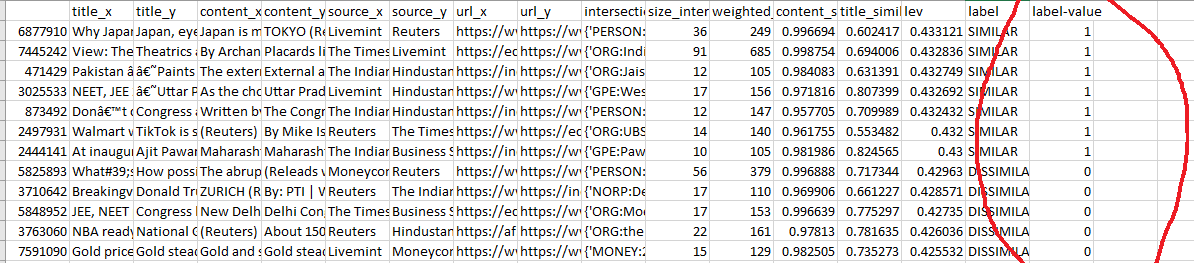
But we don't have such a dataset. It takes some investment and human power to create this. Meanwhile, what do we do? We engineer a heuristic technique.
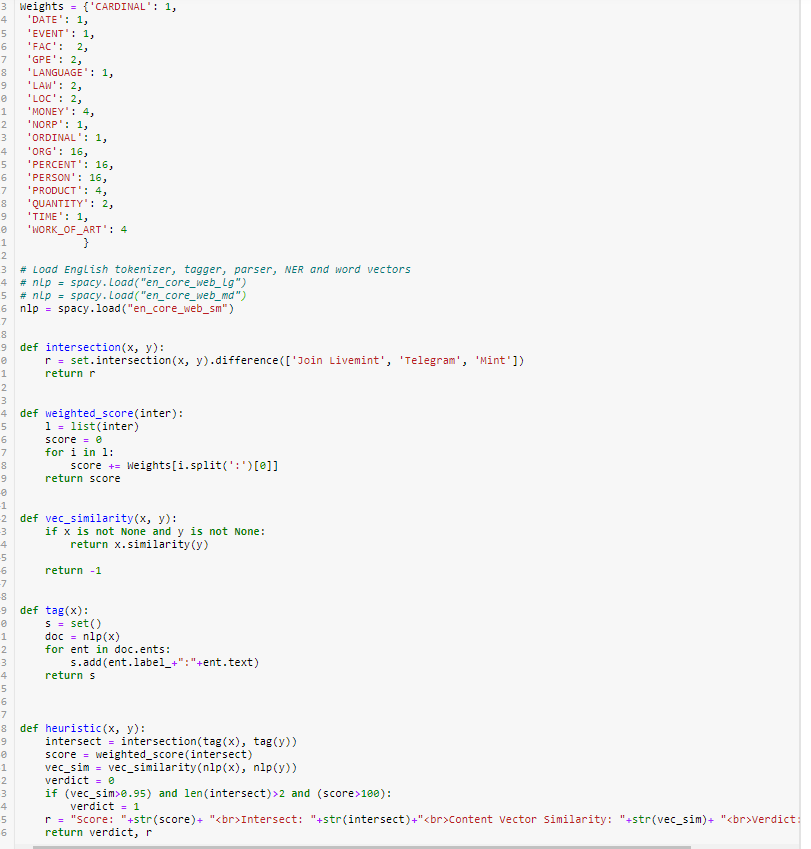
Try this out, this is a simple web flask application. You input two news stories and it predicts whether two stories are paraphrases of each other
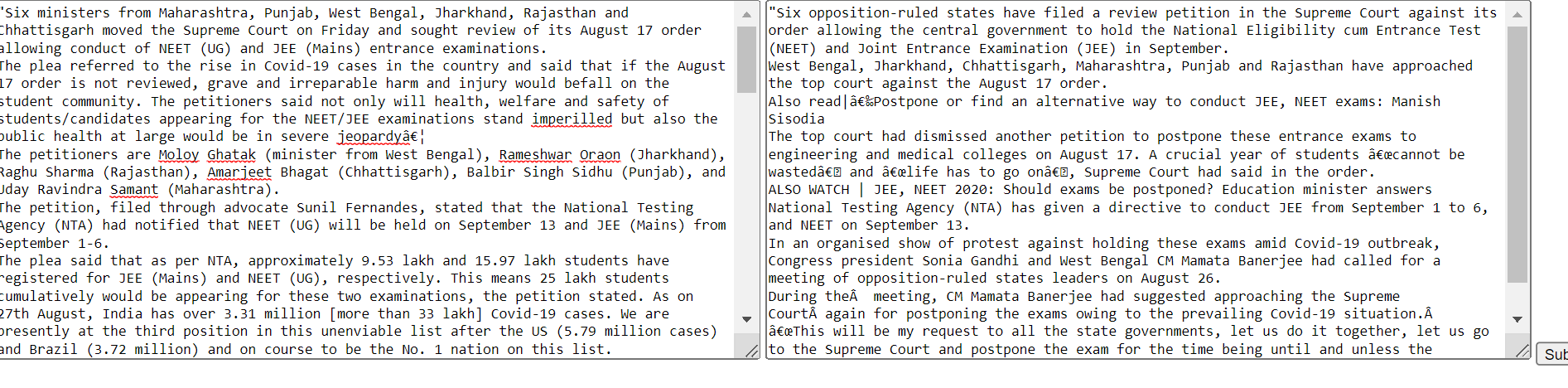

Please find the code below
 GitHub
GitHub
In the following code we use News API that scrapes through major news sources.
We scrape through news api and generate daily groups of similar news stories.
GitHubIn this code I use en_core_web_sm
nlp = spacy.load("en_core_web_sm")
In the produciton code I use en_core_web_md
en_core_web_sm does not have any word vectors and the vector similarity bit does not work. This has an impact on the accuracy.
For one company, I created a benchmark dataset of 200 pairs of news items. I was able to demonstrate the following metrics on that test data.
(Accuracy = 87%, precision = 79%, recall = 89%)