

Problem Statement
Given a pair of news items — Ni and Nj, we want to know if Ni and Nj are talking about the same event/thing/news.
Say we have a large set N of 10,000 news items. And create 10,000C2 pairs of (Ni, Nj) such that i,j are between 0, 10,000. Our problem statement is to come up with a function f, such that
f(Ni, Nj) = 0, 1 — where 0 is the output where Ni and Nj are dissimilar and Ni and Nj are the similar news items.
Alternativelyf(Ni, Nj) = p — where 0<=p<=1 and p is the strength of similarity/probability that they are similar news items

A more nuanced approach would be to treat this as a multi-label classification problem. This would also mean a more sophisticated training data set. But this discussion is in the next post:
Incidentally, I have solved this problem without any explicit supervised learning (word vectors from commercial NLP libraries have been used) engineering a heuristic method that works fairly okay but not perfectly. Check it out here:
Problem of Machine Learning?
Machine Learning is typically used to obtain such a function f. Machine learning is in fact a science that gives us a function, given a huge training data of sample input and output.If f(x) = y. ML finds out “f” given x,y
However, we could also solve this heuristically — just come up with our own engineered function something like (0.8 * (number of common words)+0.9 * (number of common people referred)/5 which gives an output 0→1
Or even an algorithmic functiondef f(Ni, Nj):
if (date in Ni == date in Bj):
return 0
else:
return 1
The promise and proposition of Machine Learning techniques is that statistical methods can give better accuracy than the above heuristic and/or logical methods.
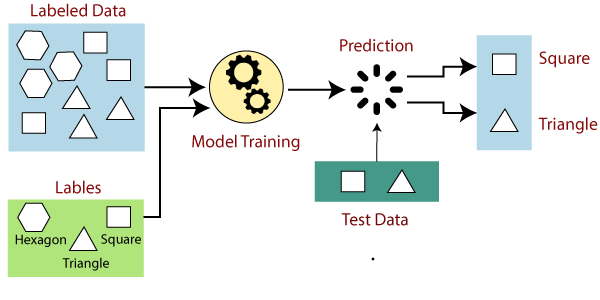
Supervised or Unsupervised Learning
Do we know the output we are interested in? Yes we do. We know what we are looking for — namely, Similarity. Let's say we give 2 news items to a human being. Can she confidently tell if the two news items are similar? YES! Thus this is clearly a problem of Supervised Learning.
If, in stead we just had a corpus of 10,000 news items and we did not know what we are looking for. We just wanted some patterns/clusters in this corpus then it would be a problem of unsupervised learning. An unsupervised clustering could lead us to any form of clusters — not necessary that of semantic similarity. It could be clusters based on Voice, on Category, on Style, on number of words, on Complexity, on syllables used. The possibilities are endless.
Moreover most of the time we don’t know what the cluster returned by a K-means or a hierarchical clustering algo — even means. It will just return sets of news items and claim they are similar. But in what way? That a human being will discover on examination of these clusters.
But we already know what kind of clusters we want — that of semantic similarity. We care about a specific kind of similarity — is the news item referring to the same story as the other. So why do unsupervised learning and clustering? We know what we are looking for — we shall supervise the learning.
The simple question to ask is — do we have labels? Yes, we do — Similar/Dissimilar. These are the labels. This is what we want to predict. If we have labels, the problem is supervised.
Thus it is a problem of supervised learning.
It is a problem of binary classification.
Problem Statement of Supervised Learning
Given a large dataset of the tuples(Ni, Nj, p) — where p is 0 or 1Run a supervised learning algorithm such that we obtain a function such that if two new news items Nk, Nm, are entered into a function then it should correctly predict whether they are similar or dissimilar.
Our thesis is that there exists such a function in the world such thatf(Ni, Nj) = p , where p is 0 or 1We are on a quest of this f.
Ofcourse there exists such a function. Our human being in the above example employed it in his brain. Our algo needs to immitate her. It will be worthwhile to pause and think why the human being thinks the two news items are referring to the same thing? If you ask you might receive answers such as —The same date, organizations, people, locations, events are referred to in both. Let's make a note of this. We might need this later in our discussion of feature extraction.
This formulation thus becomes a binary classification problem.
Supervised ML promises to procure this f if we supply it with enough data points of (Ni, Nj, p)
How do we create a large enough training data set for our learner?
Data set creation
Ideally if we would find a ready made data set such that we have a large corpus of news items pairs it would be ideal. Let’s look online to see if there is any such data set available?
To find datasets for our purposes we will need to find out if
- this problem has already been done by some one else?
- a similar problem that is reducible to this problem has been done by someone else?
- is there a larger field of science dedicated to this kind of problems.
Turns out that Semantic Textual Similarity (STS) is famous set of problems that has a lot of industrial applications. Our problem is one of them. Which are the others?
- Paraphrasing
- Page ranking and search
- Plagiarism testing
All these problems need a similar if not the same dataset.
https://github.com/brmson/dataset-sts
https://github.com/brmson/dataset-sts/tree/master/data/sts
http://alt.qcri.org/semeval2014/task3/index.php?id=data-and-tools
A standard benchmarked corpus for STS is this:https://nlp.stanford.edu/projects/snli/
We could even start of with a neural network built on these datasets and then “transfer” the learning to our dataset.
Building our own dataset — A dataset from NEWS!
There is no substitute to getting the training data from exactly the same pool from where your live examples will come. So irrespective of whether we find a good general dataset that helps us tune our learner to getting textual similarity, we certainly need to train our learner to news data — specifically our sources (moneycontrol, times etc)
Has anyone already done this?
My proposal for data set creation
- What we do is take 100 news stories
- Find 5 versions of each of the story. We have 500 stories.
- We create all possible pairs of 2. 500 C 2 = 500*499/2 = 1,24,750 pairs. That is a hell lot of a training data.
- Of these, 100 * (5 C 2) = 100 * 5 * 4 /2 = 1000 pairs are SIMILAR news stories and the rest 1,00,000 pairs are dissimilar.
- We could balance the data by throwing out half of the dissimilar pairs.
Here is a way to operationalize this:We identify 5 volunteers. Each volunteer is given a date range say April 2019 to one, May 2020 to another. He needs to create a spreadsheet with the following columns
Story title1, Content 1, Date of Pub 1, Story title2, Content 2, Date of Pub 2, …. Story title5, Content 5, Date of Pub 5,
Create 20 such quintuplets. If 5 people do this. You will have 100 stories with 5 paraphrased reports of each. 500 stories in all. From these a huge dataset can be constructed as shown in the beginning of this section.
If we find more than 5 volunteers… the more the merrier.
Voila we have our dataset for supervised learning.
A word of caution: a dataset based in just 100 real life events might bias the algo towards the words and terms in those 100 stories. It will be better if care is taken that our volunteers choose very diverse stories.
Alternative — Crowd-sourcing
Alternatively we could use our own app as a dataset creator — where we ask our users to tell us if two news articles are similar or not. We incentivize this and in a couple of months create a training dataset of the nature we want.
We could also create user interface of such a form that the user ends up putting two news items together and unwittingly informing our backend which logs it into our training dataset.
We have our training data. Now let’s start learning
Feature Extraction
So far we have treated the news items Ni , Nj as some kind of a monolithic symbols. But they aren’t. They are English strings of non-specific length — with words. And moreover, with linguistic features.
At the lowest level they are alphabets. But a level higher they are words. A level even higher is that they are nouns, verbs and such grammatical structures - “parts of speech”. But even one more level higher, they are organizations, events, people, numbers,

A learning algo , if fed, these features of Ni and Nj, will perhaps be able to decide the similarity in a better way than perhaps a simple string.
Isn't that how human beings instinctively distinguish? They see that both stories are talking about Dhirbhai, Reliance, in Mumbai on 28th Aug. Chances are they are the same.
But how do we extract such features? This technique is known as Linguistic Feature Entity linking. Every standard NLP package such as NLTK, Apache OpenNLP and others have "part of speech taggers". These can be used alongside many high performing linguistic feature learning algos to extract such features.
We need not reinvent the wheel. A large number of commercial packages such as Spacy, Google's NLP engine have already done this tagging for us. We need to do cost-benefit analysis of these. https://spacy.io/usage/linguistic-features#named-entities
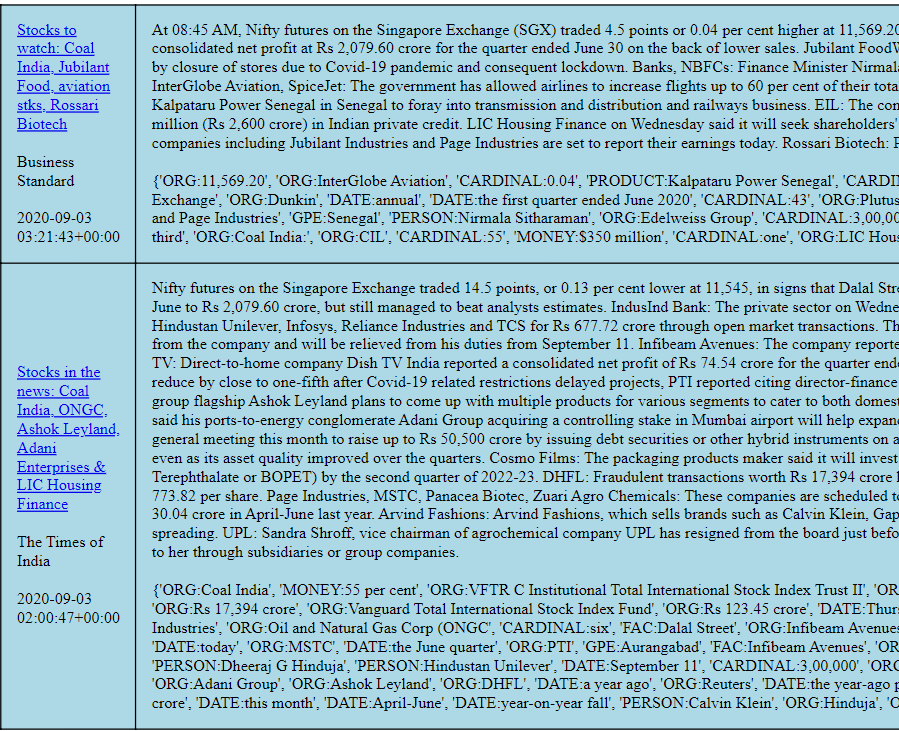
Here is an example use of this package to extract organization, event, people info from the text
 GitHub
GitHub
Thus for every Ni we can extract the organizations, dates, numerals, money, people and events mentioned in the paragraph We do the same for Nj
And we not only supply Ni and Nj but also supply these to the learner — or perhaps only these and not the actual news item.
Feature Vectors → Word Vectors
In stead of feeding the entire news item, we could just feed the learner with the word vectors of the organization, person, date, geopolitical entity (location) extracted from the text. A word vector is a matrix (vector) representation of a word.

News Vector → Paragraph Vectors (Doc2Vec)
Imagine if every paragraph could be represented by a vector such that the lesser the distance between that vector and another paragraph vector, the closer it is to that paragraph in meaning.If we can create paragraph vectors for each of our news item then that can be one important and perhaps only input to our learner.
We could use a ready to use paragraph vectoring api — if there is one — or create our own.
https://spacy.io/usage/vectors-similarity
Gensim
There are other industry standards for Doc2Vec such as Gensim
https://www.tutorialspoint.com/gensim/gensim_doc2vec_model.htm
We can use Gensim to create vectors out of our news stories.
Alternatively, a lot of others have tried out Doc2Vec implementations. We can start with one and then engineer better and better ones.E.g.https://www.kaggle.com/alyosama/doc2vec-with-keras-0-77
Learning architecture?
We will need to try out various architectures from neural networks such as LSTMs, to simpe MLP (FCN) to Random Forrests and even perhaps simple logistical regression.
This is after all a binary classification problem.
Semi-learning Alternatives
If you don’t have a large dataset and are finding it hard to create one. There is a quick and rough solution. Use paragraph vectors, feature extraction and manually engineer a heuristic function just by “looking” at the values.
- calculate the distance between the paragraph vectors
- distance( V(Ni) , V(Nj) ) = d
- Find number of common organizations — o, people — n , date — t , event — e, numerals — l.
- And create a dirty, rough, guess-work, trial n error, heuristic function
- if (d < 0.7 & o >3 & n >7 ….) then return 1 else return 0
It could even be as simple as:if more than 80% organizations mentioned are matching, if more 75% of persons mentioned are matching, if more than 90% of the GPEs are matching and the date of publication is 1,2 days near then it is the same article.
This is not supervised machine learning. The Paragraph Vector creation is the only learning bit in this solution. But it might just work!
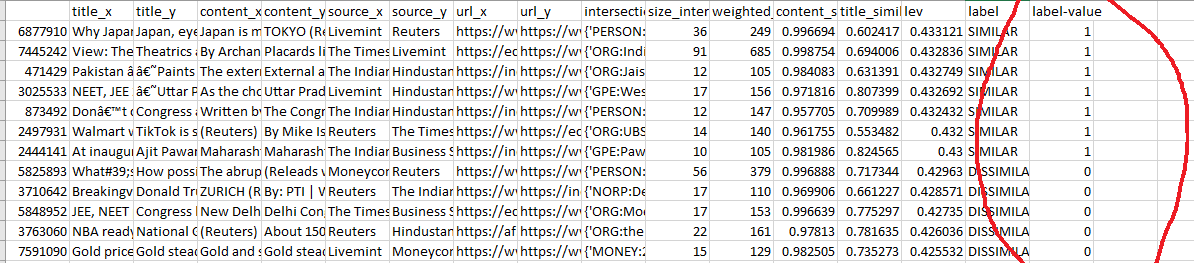
Here is an example of what I mean by this. This is Python code that has given some interesting results (please look at the CSV)
GitHubMetric of Quality
How do we measure the quality of our result? There are various ways in which machine learning/prediction results are measured.
- Accuracy
- Precision
- Recall
- F1 score.
Which of these four metrics to apply depends on what matters to us most — maximizing true positives? minimizing false negatives? or both?
- For instance in Cancer Prediction — a false negative can be very harmful! In such a use case “Recall” is the most important metric.
- In anomaly detection — false positives is what we want reduce, here “Precision” matters.
- F1 take all three into account.
In this case, if we a call something similar when it was not (False Positive) is a more expensive mistake than if we call something dissimilar when it was similar. (False Negative)
In this case we don’t care too much about false negatives. We want to reduce false positives. Thus we should be tracking Precision. i.e (TP/TP+FP)
A Commercial Word of Caution
There might be a temptation to treat this as a scientific problem. For us, it is not. It is a commercial problem and thus our first focus should be to find out APIs, packages and existing solutions. Apply them.
Anything — such as Spacy — that gives ready made solution should be primarily used. That should be the highest priority. Any prediction that is better than RANDOM, is a great result to start with. We then engineer to improve it. We are not writing a scientific paper but getting a working prototype out.
Can this be a multi-label classification problem?
Turns out that we could complicate the matters a little further. Why settle for just binary decisions of similar/dissimilar? They show no nuance, of the kind that actually exists in journalism. Please read the following to see a more nuanced approach.