
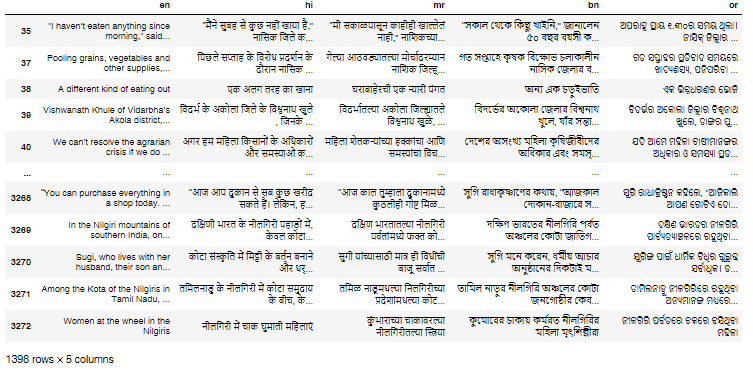
People's Archive of Rural India (PARI) has a rich database of translated content, created by a superb team of translators that is led by Smita Khator. Talented linguists and writers such as Qamar Tabrez and Medha Khale translate PARI's English content into major Indian languages.
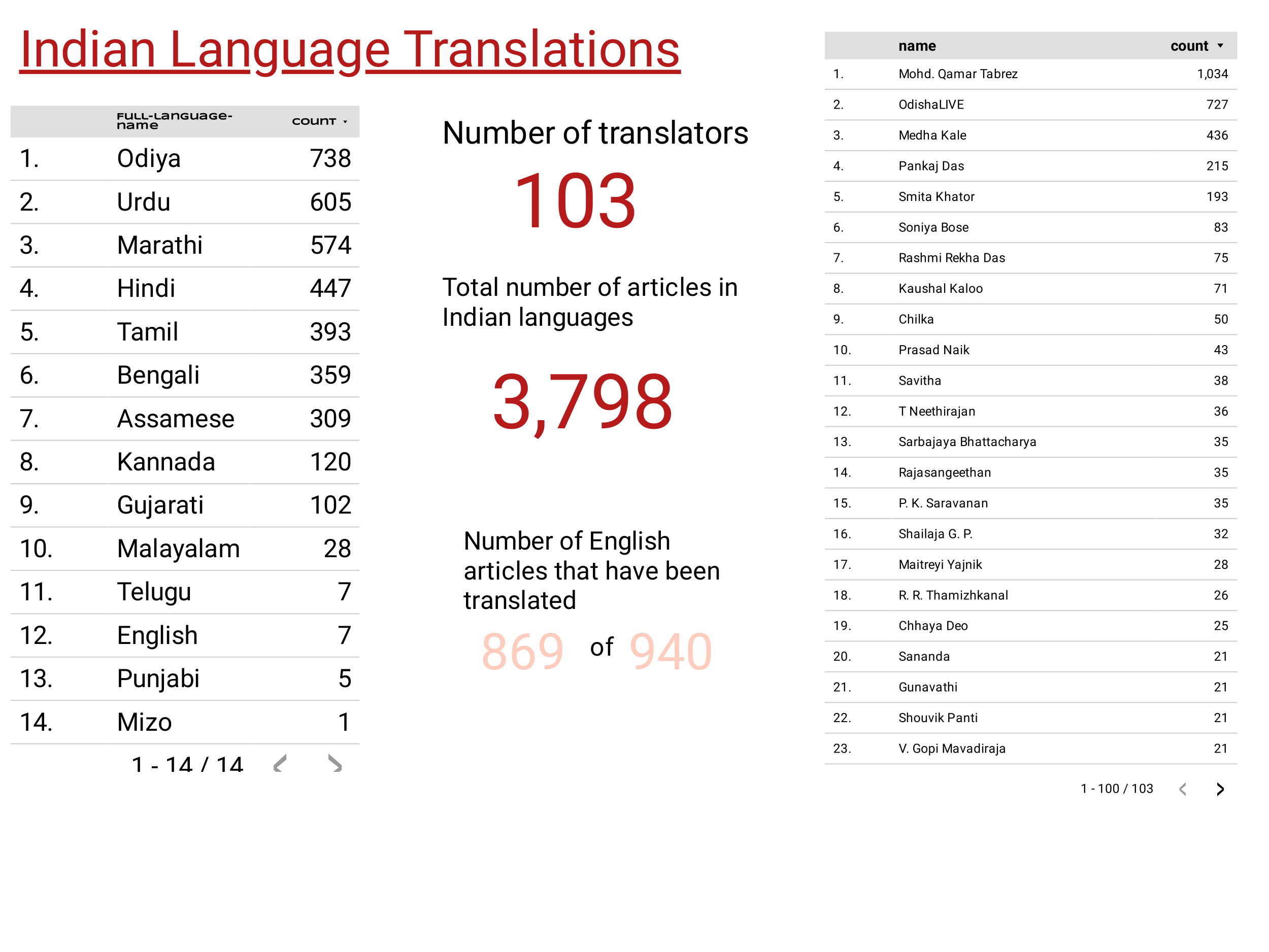
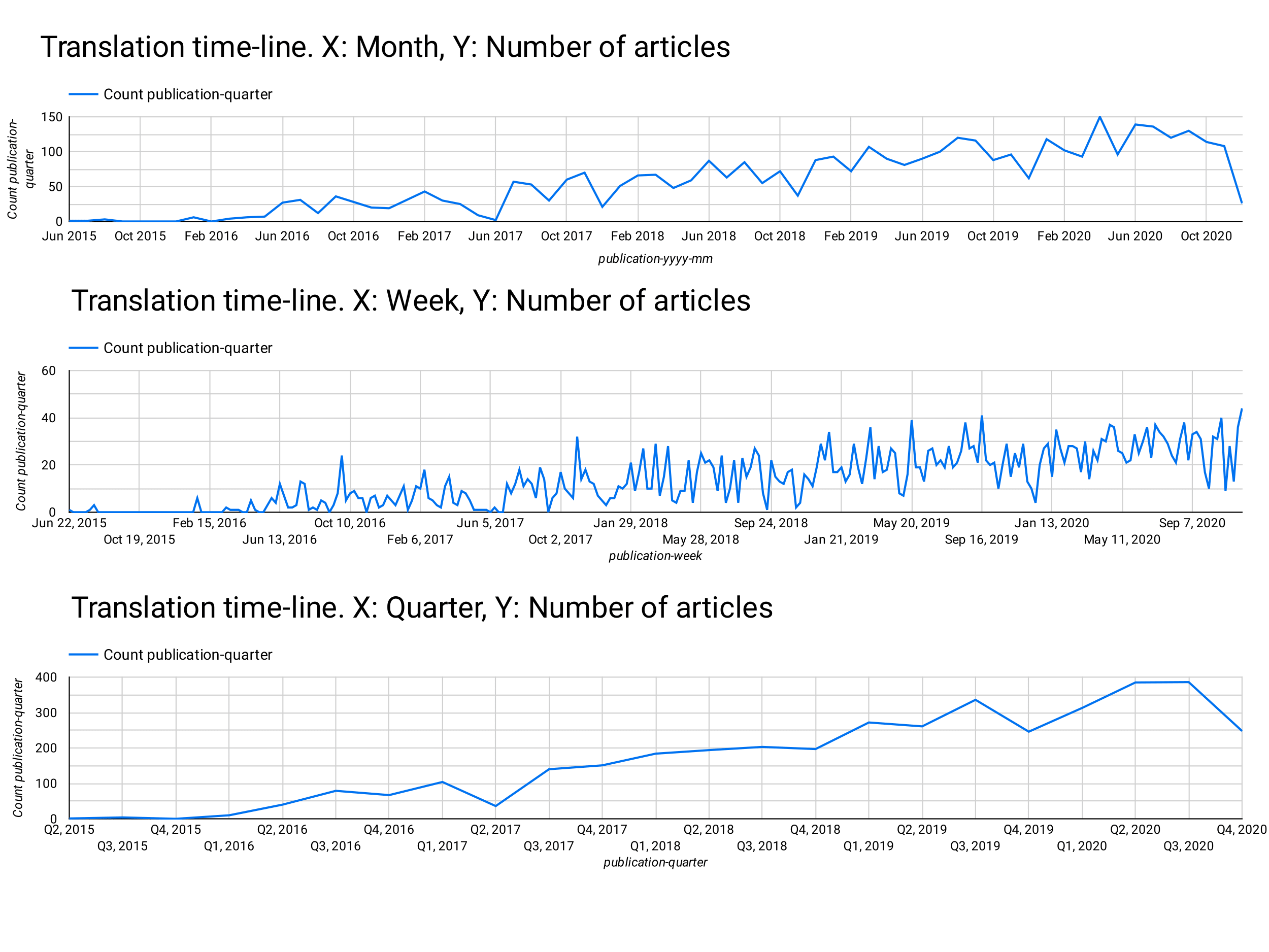
Can we build a translation memory to make it easier for new translators to use the same terms and abide by the idiom set by previous translators?
Special thanks to linguist, Dr. Qamar Tabrez, PARI's prolific Hindi and Urdu translator for this superb idea.
First let's cache language paragraphs on local storage. The query is quite heavy and we don't want to hit the database frequently during our experiments. For shicks & giggles I thought it'd be a good idea to do this in Java. It isn't. Don't try this at home. Do it in Python. Much simpler.
 GitHub
GitHub
Now as have a directory of text files with paragraphs of text.
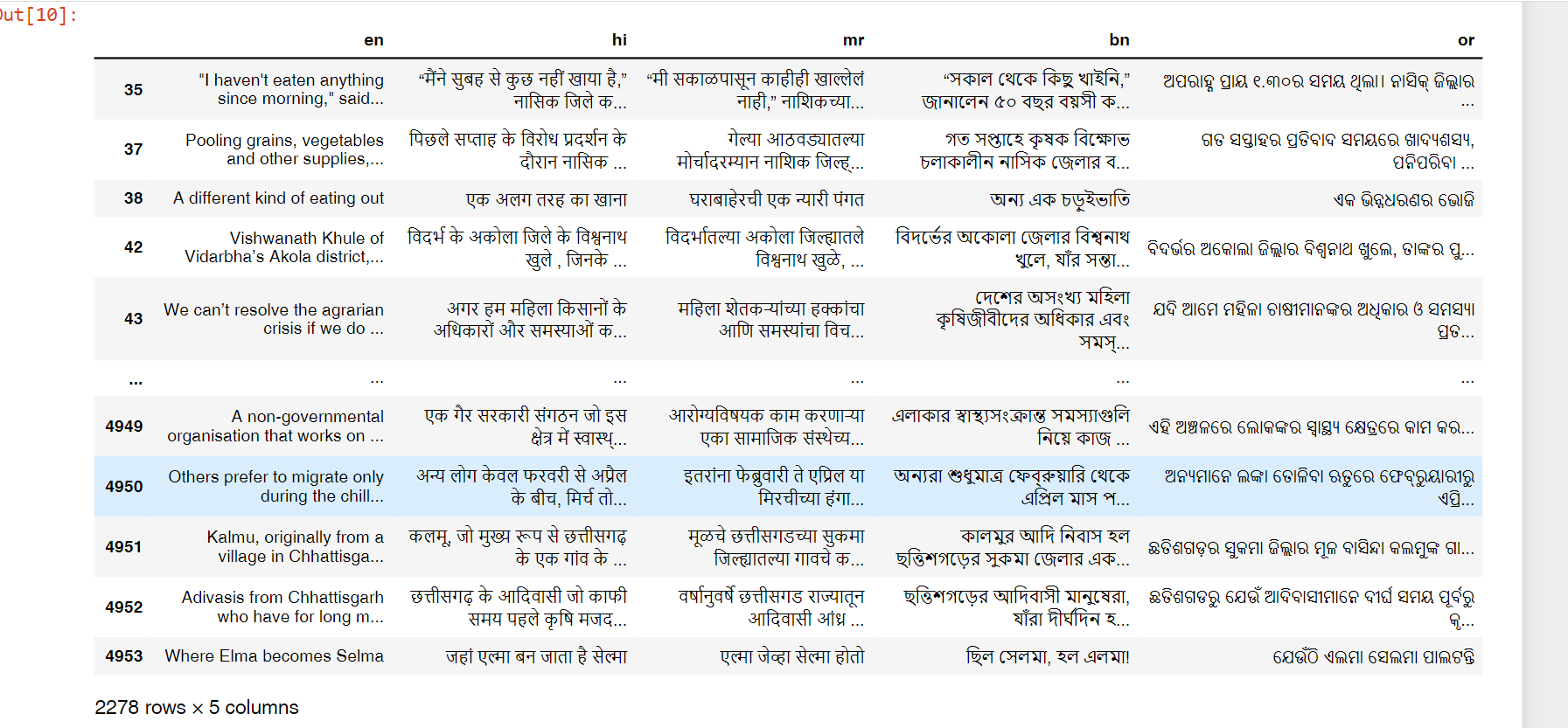
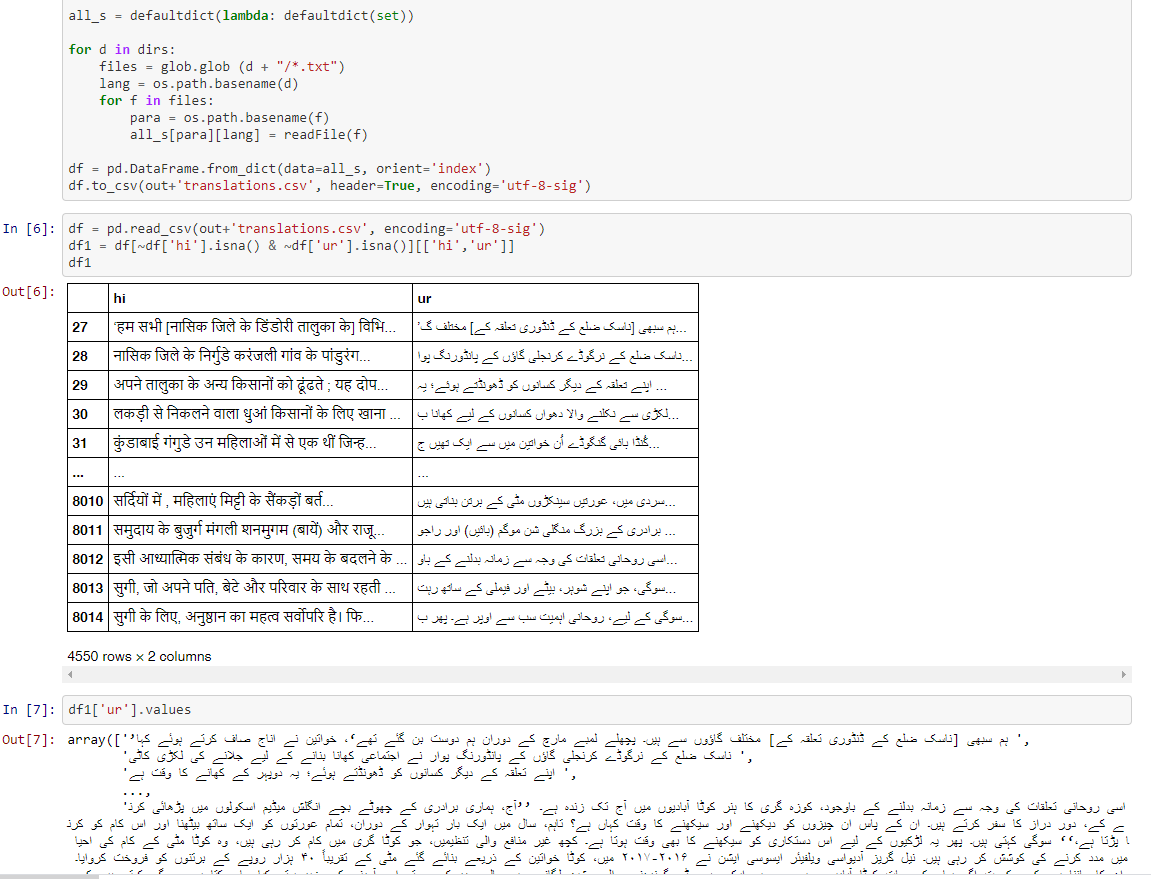
Now create csv file from these files to juxtapose paragraphs that correspond to translations of each other.
Please see the entire code here:
GitHubNow all that remains is to create a Wagtail plugin or even a Chrome plugin for the web user to find the relevant paragraphs where one can find the perfect translation of a word.
Some questions that I wish to answer are:
-
Are 4550 Hindi/Urdu paragraph pairs a large enough dataset to train a transformer network for transliterating/translating between Urdu and Hindi?They are after all two registers of the same language.
-
Can this dataset be used to compute a kind of distance between languages that can corroborate the lexcical and syntactic similarities between languages of the same linguistic group?