
Foreword
In the previous post,

I had proposed that we frame our news item grouping and similarity problem as a Binary Classification problem where news items are classified using various techniques of Semantic Textual Similarity (STS).
I had propose 2 broad approaches:
- Supervised machine learning approach
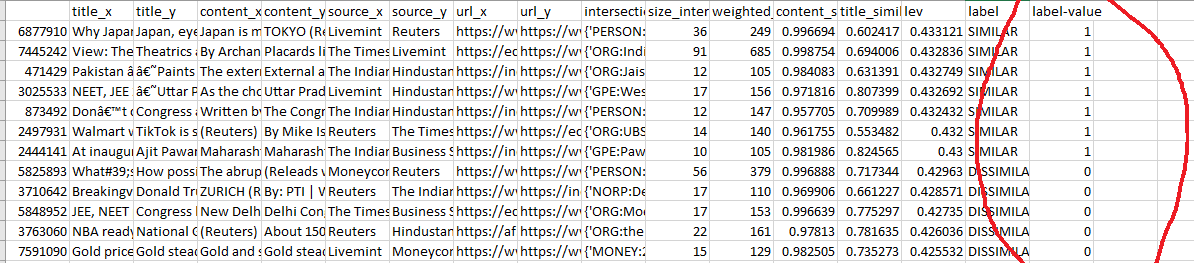
- Here where we are required to create a large binary labelled training dataset. This dataset establishes the correlation between various features of pairs of news content and the final label assigned to the pair — similar (1) or dissimilar (0)
- We are required to make feature engineering choices. That is to say, that we train the machine by feeding it
- Cosine difference (and other comparative distances) between the document vectors of the news content pair respectively
- Cosine difference (and other comparative distances) between the sentence embeddings of the title.
- Intersection set or some weighted score of the named entities (such as orgs, people, etc..) recognized by such commercial software as Spacy.io

- Heuristic “Jugaad” approach
- Here we don’t employ machine learning. Why? Because we don’t have enough labelled training data. In stead we take the features that we identified above — cosine distance between doc vectors, weighted score of the common named entities and perhaps other metrics such as the levenshtein (edit) distance between the titles
- -- and we engineer a jugaad equation and threshold — or logical function — out of all these metrics, such that this threshold comparison or function returns 0 (dissimilar) or 1 (similar).

if (['content_similarity']>0.95) & (['size_intersection']>2) & (['weighted_score']>100) then return 1 #SIMILAR else reutrn 0 #DISSIMILAR
There are 2 main differences between the two approaches
- In the second approach our coder jugaads a heuristic function that return boolean for similarity/dissimilariy. In this approach the human coder peruses the data available to her and designs such a heuristic through trial and error. In the first approach the machine essentially automates the human jugaad and constructs this function.
- So that the machine is able to beat the human being in perusing the data, the machine needs training data with input/label rows as shown in fig. 1. . Approach 1. hence needs a huge training dataset. This training dataset needs to have correct labels (“Similar” or “Dissimilar”) assigned to pairs of news content. These labels need to be human supervised and accurate. This is a mammoth undertaking that can only be done with incentives for the human data entry participants.
The Data Wants to Know! - vagaries of journalism.
In this post, I propose that what I formulated as a binary classification — labels = 0 or 1 — is in fact a multi-label classification problem.
In modern newsrooms, a large number of reports come from news agencies and syndicated content. This is why, many a times, we will see the same PTI or Reuters — both news agencies — report carried by Moneycontrol and Times of India.
There is however, a catch — the titles or “headlines” of a news items is the mandate of the editor of the newspaper. Thus it is possible that identical reports with nearly the same content will have totally different titles. Additionally,
Secondly, it is well within the purview of the newspaper — and they often exercise this prerogative — to change only a few phrases in the news agency copy before carrying it. Thus the exact same report will appear as distinct strings to the computer. (Here is where the metric levenshtein distance comes handy)
Thirdly, we might not want to show various versions of the same Reuters/PTI report to the user.
Lastly, on the same day two newspapers might refer to the same event — fed raising interest rate as — “Fed raises interest rates, causing the market to crash” , “Copper rises after interest rates hiked”
I propose that we introduce nuances to the similarity level of articles. This way, the news app ui will be able to make better decisions pertaining to User Experience on the exact kind of similarity. That is, news app ui may chose to act differently to same articles from news agency vs. those that are different takes on the same event.
When I fetch news data from news api, I see mainly 4 kinds of relationships between article pairs.
- UNRELATED:
- RELATED
There is typically a chronology here.
- PARAPHRASES
- IDENTICAL
Another scheme of classification
Another scheme of classification would be to classify a pair of news items with their real life journalistic phenomena. For example
- Unrelated
- Same real life event different outlets
- Same Agency Report in different outlets
- Identical reports in the same outlet
- Chronologically related articles
- Topically related articles
This might be better for the App UI to make decisions.