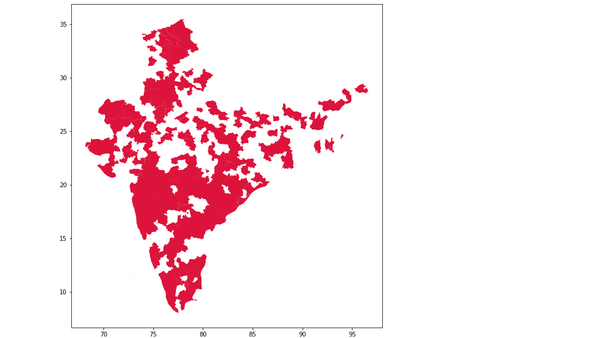
datascience People's Archive of Rural India (PARI) Coverage on a Map PARI's articles, faces, albums and images are from rural India. We want to see how much of rural India has PARI covered?
Deep Learning Deep Fashion Can a machine imitate the mind of a fashion shopper? When an retail user views an image of a fashion apparel, her/his/their mind goes through a complex decision making process.
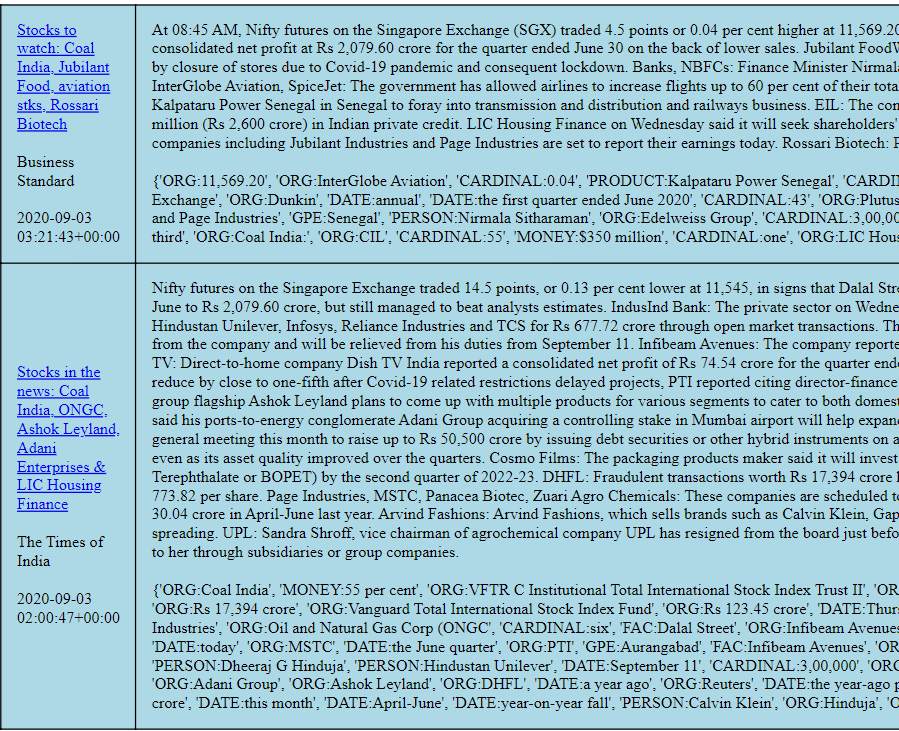
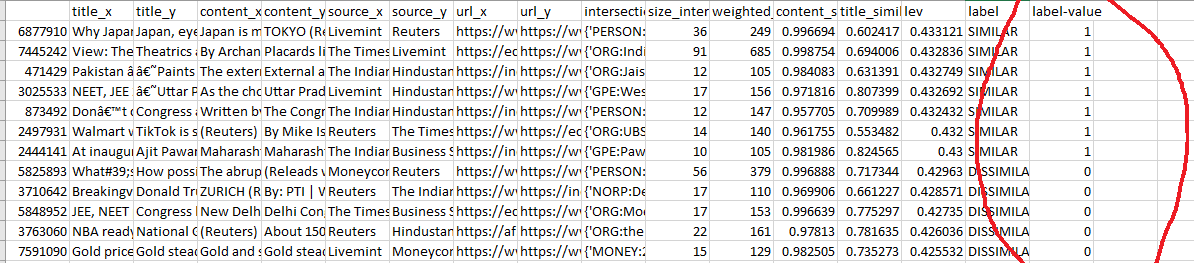
NLP News Similarity Problem - NER solution How does one know if two news items have the same story? This is a problem for news aggregators. Multiple sources supply news content that are paraphrases of each other.
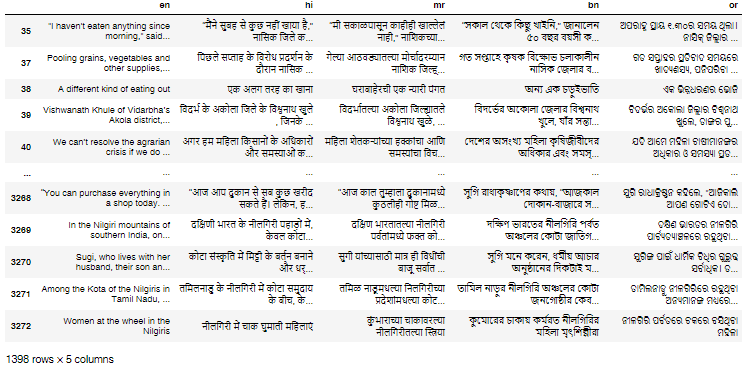
NLP PARI Translation Memory A translation memory makes it easier for new translators to use the same terms and abide by the idiom set by previous translators.
News Similarity — a Binary Classification Problem Problem StatementGiven a pair of news items — Ni and Nj, we want to know if Ni and Nj are talking about the same event/thing/news. Say we have a
machine learning News Similarity — a Multi-label (one-hot) Classification problem ForewordIn the previous post, News Similarity — a Binary Classification ProblemProblem StatementGiven a pair of news items — Ni and Nj, we want to know if Ni and Nj are talkingabout the
machine learning What is Machine Learning? What is machine learning? What is the Machine learning? How is it related to AI, NLP? How do you measure the quality of ML? What are accuracy, precision and recall?